
Excelsium
Member-
Content count
99 -
Joined
-
Last visited
Posts posted by Excelsium
-
-
OS selects where the file be saved and i don't know how does it decided it.I just will try to fix the crash and you will see whether it will correct your problems. That's all I can do.
Yea it just seems extremly bizzare, unbelievable (For it to be a bug in hardware/os/etc) that it would happen repeatedly on the same files with the same TTH, but succeed on all other files (in Segmenting mode)
I understand your saying its a bug somewhere in my machine (and my previous machines) but for it to be that specific seems unbelievable.
My thinking is that bugs like that happen randomly on random files
Its clear for reasons stated that this is an incredibly specific precise "bug" with no apparent randomness to it.
Theories: (maybe posted some of these earlier).
1. StrongDC segmenting download technique*1 is detecting that peers copies or chunks are corrupt*2 when they clearly are not*3 (False positives) and is preventing the completion of that chunk and therefore the completion of the download.
*1. Has and is using a corruption detect technique of its own
*2. A small percentage of files, perhaps a tiny percentage of the overall files shared using DC++
*3. As proven by testing
1.2. Something else in StrongDCs technique is causing false positives in an extremly specific manner.
1.3. StrongDC is corrupting specific files, detects its own corruption and prevents completion.
Theories of bugs in my machine:
1. An amazingly specific bug ???
2. ??
add more later

Reply to post in crash+bug forum.
QUOTE(Zlobomir @ Mar 30 2007, 05:58 PM) *
Again I have to double post, excuse me BM. But what about the file in question is really ok, runs perfectly, etc., after downloading in some other way. And Excelsium, please send me again some small files for tests, or even better, attach them here.
Yes, you are true. File can have correct TTH and can be 100% if it has been downloaded in other way than segmented.But again - it's only this situation.
Let's talk there is some HDD error (just guess, it can be also memory error etc.). This error appears on clusters G and U.
Current situation, user downloads file using segmented downloading and Strong/Apex tries to save them into cluster G. So what happens? Yes, file will be corrupted. Normal downloading saves the file to cluster A, so file will be OK.
Another situation, user downloads file using segmented downloading and it will be saved to cluster J. So no file is OK! But later he wants to download another file using normal downloading and OS selects that it will be saved to cluster U. So where are we now??? File will be corrupted using normal downloading.
I hope, that now the problem is understable.
But I also realized another situation. The question is, when the corruption occurs. Before crash or after crash??? But time can't be detected, because Apex/Strong will report the corruption when it's detected, but not when it occurs. what I want to say:
a) corruption occurs before crash -> so when it is detected, Apex/Strong wants to fix it and it crashes during fixing. This means some HW bug in the PC.
 corruption occurs after crash -> Apex/Strong crashes and file gets corrupted due to the crash (because OS doesn't flush to disk).
corruption occurs after crash -> Apex/Strong crashes and file gets corrupted due to the crash (because OS doesn't flush to disk).Both situations mean that the crash must be fixed. But in A) it won't fix corruption messages.
I know that now you will say "it's really situation
", but you can't say it, because it can't be decided 
I think Its a bit of situation A and a bit of something else.
What I mean is. I think there is a problem with the technique causing false positives or real corruption due to itself (a bug somewhere in the technique of Strongdc) -
And then it crashes after the false or real corruption that it has falsely detected or caused.
See the list of thories above, this is my current one.
On emulation: I don't use it for those hubs or any others - If I come accross a hub that requires it to connect, I don't use that hub because of some issues I heard of.
Users downloading from when it crashed?:
1. The crashes are not very frequent since I usually spot the problem and pause the file before it crashes.
2. I have not been logging the users it was downloading from when it crashes.
I'm probably not going to do any more testing with segmenting mode until a new version of strong/apex is released or someone has suggested configuration tweaks I have not tested.
On my machine:
I'm still thinking about the hard drive clusters and will add to my reply if needed.
But for now heres what I know.
1. My hdd has no problems: defragmented, 0 bad sectors/problems reported by S.M.A.R.T, 0 problems reported by windows tools
2. How can that problem affect a specific set of files with same TTH indefinetly?, files are written in whatever free space (clusters) is available.. which is random.
All the other details have already been posted I'm sure. for example
"Perfect copies of files can be downloaded using normal mode but cannot be completely downloaded using segmenting mode for the same specific files with same TTH"
Again 95+% succeed in segmenting mode, the exact same (No ramdomness*) 1-5% have the download not completing problem in Segmenting mode.
*Randomness characterizes the data layout on a disk, and RAM aswell.
But this is clearly a precise bug, maybe you have some details on how a hw or sw defect or perhaps configuration setting outside of StrongDC/apex could result in this very precise bug affecting a set of files with the same TTH indefinetly?
Another reason why this workaround should be implemented:
(At the very least the client should pause the download and warn the user to prevent slot and bandwidth wastage, and save the user time identifying the corrupt files)
When the crash is fixed the client will be left to continue to download the same chunk(s) over and over again until the user returns and spots it, of course sometimes they wont spot it. - Wasting slots and bandwidth in the network. For me thats 18hrs a day of unsupervised waste.. except weekends.
Of course I'll leave segmenting disabled but what about others who dont know about these issues yet? I know I've been experiencing it for a long time with various machines but only just taken action to deal with it - If I had not taken action I would waste many more gigabytes of bandwidth without the crash fix but with the crash fix I would waste 2x or 3x+ more.
I've a 10mbit connection, I know I've easily wasted 100s of GB's of my own and others bandwidth because of my ignorance of the only known existing workaround (segmenting set to disabled), for example a good percentage of that on popular files with 100+ sources - always maxing my connection.
I started using RevConnect in 2004 - I've been wasting slots and bandwidth for all that time, about 2 months ago I moved to StrongDC>Apex (easier on the eyes) because of these issues but was disappointed to find they are in these clients aswell, so I began my quest for a workaround here, luckily I found one not ideal.. but it works (Disabling segmenting).
The potential that this kind of waste can happen has to be stopped and of course the ongoing waste by people who have the issue, are ignorant of it and have not disabled segmenting - via an automated method.
Options:
1. Detect corruption and pause the file, put error in the error column.
2. Detect corruption and switch technique for the file.
-
i doubt that you had and you will always check TTH of downloaded files. Normal way just doesn't show the message and normally saves the corrupted file to the disk.Ok thats a misswording on my part. the facts below and above still stand.
I'd like some detail on how it would be a HDD/memory bug that causes the exact files with same TTH to fail over and over in segmenting mode when starting from scratch even starting with a default clean install of apex/strong.
Again - downloading these files in normal mode complete fine and are verified (checked and matched TTH) against a copy another source (bittorrent) and are fine in extensive subjective testing. So I think that destroys the theory that these files are corrupt and the segmenting technique is detecting corruption in the peers (all peers) copies and preventing completion.
-
Why you can't understand me?So again:
Today you download file using segmented downloading and it gets corrupted.
Two days after you will download another file using normal downloading and it gets corrupted too.
Corruption doesn't depend whether you use normal or segmented downloading. It depends on actual memory/HDD position (according to where the bug in your PC is)
I've never had a problem with normal downloading
.And its always the same files with the same TTH that fail in segmenting mode even starting from scratch. deleting temp file etc. the other 95+% of files dont have this problem in segmenting mode.
It just takes a few other people to try downloading the same TTH in segmenting mode to prove it either way.
-
Yeah, but he pretends that when file is downloaded via http or torrents, all is OK in terms of accessing... erm? Or he is using AVIPreview?I check the TTH for the copy downloaded (downloaded completly without any errors) from dc++ peers (with segmenting disabled).
and the copy downloaded with Bittorrent. - they match
I've viewed both copies in full of a few such cases, and scanned quickly through the rest - I've tested the TTH in all cases and all have the same TTH, but why would there be a problem? they all have the same TTH.
I use PowerDVD 7 with the default install of codecs from divx.com to view the files, no other codec packages etc are installed.
I am happy with ApexDC++/strongdc running without segmenting mode - I have no problems whatsoever, but it would be a nice extra to have workable segmenting.
(reply to post in bug+crash forum)
I just can't understand why you can't understand that you have bug in your PC. There can't be any switching, because it's useless. Maybe file ABC gets corrupted in segmented downloading but it's ok for normal downloading. But file RKX will be corrupted only for normal downloading, but you won't see any message informing about corruption. Same thing will happen when you will copy file ČŘ -
Again I have to double post, excuse me BM. But what about the file in question is really ok, runs perfectly, etc., after downloading in some other way. And Excelsium, please send me again some small files for tests, or even better, attach them here.The smallest files I download are very rarely some image files and audio files, and I don't remember having problems with these - If I did I probably just erased from the queue and forgot about it. Currently I only use DC++ for files 100-300mb video files, maybe the odd video file 10-100mb
My earlier post:
Update: Incase you havn't encountered some problem files for testing here are some examples:
they are only a problem in segmenting mode.
search " mushishi 03 .a" and get file with TTH: HBBAHIWV56PEJQD5H6S6J4WAFQ2J3ELRNYBMJUA magnet:?xt=urn:tree:tiger:HBBAHIWV56PEJQD5H6S6J4WAFQ2J3ELRNYBMJUA&xl=189263872&dn=%5BC1%5DMushishi_-_03%5BXviD%5D%5BF334DBDF%5D.avi
search " ghost in the shell 24 .a" and get file with TTH: FY6T6IN2MEZCXWCNDL6HMAWP4HX6I2RRXRNBY2Y
magnet:?xt=urn:tree:tiger:FY6T6IN2MEZCXWCNDL6HMAWP4HX6I2RRXRNBY2Y&xl=186181632&dn=Ghost+in+the+Shell+-+Stand+Alone+Complex+-+24+%5BLMF%5D.avi
hubs with these files:
testhub.otaku-anime.net:555
public.otaku-anime.net:555
walhalla.otaku-anime.net:555
shinto.total-anime.net:666 (requires registration to search)
-
I just can't understand why you can't understand that you have bug in your PC. There can't be any switching, because it's useless. Maybe file ABC gets corrupted in segmented downloading but it's ok for normal downloading. But file RKX will be corrupted only for normal downloading, but you won't see any message informing about corruption. Same thing will happen when you will copy file ČŘ -
Thanks for helping
my poll choices (I edited the poll so my votes were removed):
x Yes, with "corruption detected at position" in the status bar, but I have tried and succeeded in downloading the same file(s) in regular DC++ client or with Muti-Source disabled.
x ApexDC++ crashed.
x I dl LOTS of files.
-
I've posted something in the feature request forum and a poll in this forum :P
-
I think the most accurate version of my arguments come across in post #157 onwards.
For ease of writing this I have defined bug to mean several things.
- "problem, issue, lack of technique, gap in technique"
- Solutions to prevent waste caused by gaps/lack of techniques in the segmented download technique.
- To inform the user about the problem, not fix the problem.
- To automate the detection of failing downloads so the user dosn't have to.
New Rewording
For Big Muscle: Helpful rewording.. of the entire thread perhaps... although If you need full detail on the waste that occurs to convince you the bugs need fixing, check the rest of this post.
Issues with the segmenting download technique
1. Redownloading the same chunk(s) ad infinitum of a download with a corrupted temporary file that is beyond repair by itself. - It should stop the process and inform the user of which temporary files are corrupted in this case or it should at least inform the user with a dialog box.
2. Its corruption handling technique to repair corrupted temporary files does not have a high enough success rate, other P2P applications have a much higher, near perfect or perfect success rate.
Issue 2. is a/the cause of Issue 1.
I once described these bugs as "download same chunk ad infinitum bug caused by inability to correct corrupted temporary file bug".
Description of the issues
1. A Corrupt temporary file for a download queue item exists on the users machine.
2. In some cases StrongDC++s segmenting download technique fails to repair the corrupt temporary file indefinitely. (Other P2P clients never fail at this or fail at a much lower %)
2.1. The segmenting download technique downloads the same chunk(s) of the file ad infinitum.*1* *2*
*1*. Ad infinitum meaning: Its been running for days: It redownloads the same chunk(s) 100s-1000s of times at high speed (10Mbit connection) from 1-10 peers at the same time (Max is 10).
*2*. The user is not informed which temporary file is corrupted.
2.1. Should inform the user if the corrupted temporary file cannot be repaired by itself.
2.1.2. Should pause the download if the corrupted temporary file cannot be repaired by itself.
2.1.3. Should detect if the download cannot be repaired by itself (e.g. redownloaded the same chunk(s) too many times) or some other technique.
2.2. "Informing feature" Only needs to be implemented if the repair corrupt temporary file technique is not fixed 100%. If it cannot be perfected then the informing feature is required for the few remaning % where the temporary file cannot be repaired by itself.
I have not tested leaving it (Download with corrupted temporary file) running for more than a week because of the bandwidth waste.
Addition:
One option instead of just pausing the download after a set number of chunk redownloads:
- If the corruption handling technique fails to repair a corrupt temporary file it should delete the download from the queue and re add it to the queue automatically. (Starts over with a new temporary file)
- The user could be given this option when the corruption is detected or set it to do this automatically.
- Other users have experienced these bugs. (see posts ITT)
- Other users continue to experience these bugs. (see posts ITT)
*ITT = in this thread
About this thread
New thread was moved into the old thread without my permission by forum admin, I'm in the process of cleaning it up.
Cleaning done: you can skip everything except this opening post up until page 3 after the post marked "New Thread begins after this post."
Title of thread censored: Real title:
Bugs found in the download techniques packaged in ApexDC++/StrongDC++
Previous title: [Request] Corruption detection technique that informs the user of corrupt temporary files of download queue items. - this would be an interim technique if a fully automated technique is not implemented (If the bugs in the download techniques are not fixed).
Long version of this opening post
The Request:
1. Fix the bugs so that the user dosn't have to be informed as is the behaviour of other p2p clients.
Last resort: 2. Corruption detection technique that informs the user of corrupt temporary files of download queue items.
There are bug(s) in the way StrongDC++s/ApexDC++s segmenting download techniques corruption handling subtechnique handles corruption in temporary files of download queue items.
There are also bugs/lack of corruption handling techniques in the way the normal download technique handles corruption in temporary files of download queue items.
Hence there are several unfixed bugs and lack of corruption handling techniques in the packages that are StrongDC++/ApexDC++
Facts
Please post corrections or relevant additions to these facts if required - I will post them here.
Segmenting download technique
- Does not complete a download if the local temporary file for that download is corrupt (Good)
- It detects the corruption but does not inform the user of which file the corruption was detected and does not pause the download if the corruption in the local temporary file is beyond repair.(Bad)
- It downloads the same chunk(s) of a download with a corrupted temporary file that is beyond repair (by itself)* ad infinitum (Bad)
- It cannot repair the corrupted temporary file because its technique to do so is bugged. (Bad)
- *1*Time and resource waste occurs because of lengthy manual user detection *2*.(Bad)
*1*. Hence the reason for this feature request - I am in essence asking for a technique to automate what is currently a manual process which involves guessing, trial and error.
*2*. Continually observing the transfers window and making a *Guess* which download(s) is/are not going to complete successfully due to a corrupted temporary file for that download.
2.1. The obvious bandwidth waste caused by downloading the same chunk(s) of a file ad infinitum until the user has engaged in and completed the manual corruption detection process.
2.2. StrongDC++/ApexDC++ crashes after re downloading the same chunk(s) of a download with a corrupted temporary file a random number of times. * This is the only bug so far a developer (Big Muscle in this case) has said they will fix - This fix has not yet been released.
2.2. Note: The cause(s) of the crash bug is/are unproven - the only bug I am unsure of.
Standard legacy download technique
- Completes the download regardless of a corrupt temporary file(Bad)
- Perhaps it dosn't detect the corruption in the local temporary file at all, if it does - it ignores it and completes the download.
Cause of the corrupted temporary files
Unidentified defect in the users machine:
Defect in the users machine possibilities: Hard drive, Filesystem, Windows XP, other software, other hardware.
I will add defect possibilities as they are sent in.
Corruption on the users machine is an inherently unfixable problem for all users for the forseeable future
The main variable being the percentage of corrupted temporary files.
- Hardware and software in/on the users machine can and will fail, I believe these are called
"Error rates" some RAM has ECC for example.
"1 error per 1billion operations" along those lines.
We require the tools of information to prevent said consequences quickly and effectively. (See my reply below to Big Muscles statement: "User should fix his problem on his own".)
Personal experience, opinion
I use the legacy download technique - even If I have a corrupt file - that is going to be obvious to me when I open or verify it - In my opinion It wastes much less time and resources to redownload the file and is also much less annoying compared to the lengthy manual user detection process during the download. Also even without the speed of segmenting I still prefer this option because of the cost in time and resources of manually detecting even a few corrupted temporary files - in my case I get about 2 corrupted temporary files for every 60 files that I download, although I may have been "unlucky" recently and the overall number is perhaps 2 in 150 or more files since 2004.
My relevant replies and questions left unanswered from the last thread:
that's a good solution. the number of detected corruptions would have to be defined, though; 50 is a bit too much...codewise, i think this would need a counter in the FileChunksInfo class if i'm not mistaken.
however, this is a workaround and i still prefer the client doing nothing automatically and letting the user cancel the download if he thinks he has to.
"I still prefer the client doing nothing automatically and letting the user cancel the download if he thinks he has to."
Doing nothing automatically - my translation: Not having corruption handling techniques for corrupt data on the local machine.
One of these automated techniques is to detect which files the corruption is located and inform the user of these corrupted files.
You are saying the user should not be informed of what files are corrupted, by saying it should do nothing automatically.
Rediculous amount of waste can occur in the mean time during the lengthy manual process of user detection... gone into full detail already.
So you are saying that you think this large amount of waste is acceptable. If these really are your opinions, please reply and say it more explicitly in no uncertain terms.
I'd also be interested to know if Big Muscle or anyone else reading this thinks that this waste is acceptable, clearly I think its unacceptable and I'm fairly sure the vast majority (users/devs) involved in P2P filesharing as a whole think its unacceptable but if you think its acceptable please come out and say so and state the reasons why you think it is acceptable.
Other apps will at least detect local files that are corrupted and inform the user of these corrupted files, so that the user can do something about it and quickly.
now do you understand?better, corruption in the file "was created" when it had already been saved on your HDD and connection to the remote user had been closed. It has nothing to do with network communicating!
how many users has corrupted HDD? maybe one of 1000 (maybe of more, just a guess).
I already understood exactly what you just said and agree with you.
I am asking for corruption handling techniques for corrupt data on the receiving users machine to prevent wastage (full detail-previous posts) and questions at the end of this post.
So My theory of interacting with certain peers causes the local temp file to be corrupted is extremly unlikely however possible (hackers or ???) - I was just trying to list all possibilities however likely or unlikely so we can get to the bottom of this, which we have.
User should fix the problem on his own.I agree but with an addition in this case -
-
I've finished testing "Enable multi source" set to "disabled".
Good news: No corruption messages or crashing.. all downloads completed and are perfect as tested against Bittorrent releases - remember they all fail in segmenting mode.
Problem solved I guess - I no longer have to use regular DC++ alongside strongdc or apex to catch its segmenting failings.
I'm hoping that someone builds a Detect and switch feature as I described in full earlier so others and I could use segmenting mode - Or builds a segmenting technique that is 100% instead of 95-99%
The DC++ segmenting problem has been around for years - I had the same issues in RevConnect (another segmenting DC++ client). But only recently bothered to do anything about it since the amount of files I transfer has been steadily rising.
I have changed PCs, reformatted etc several times during that period.
-
Hi
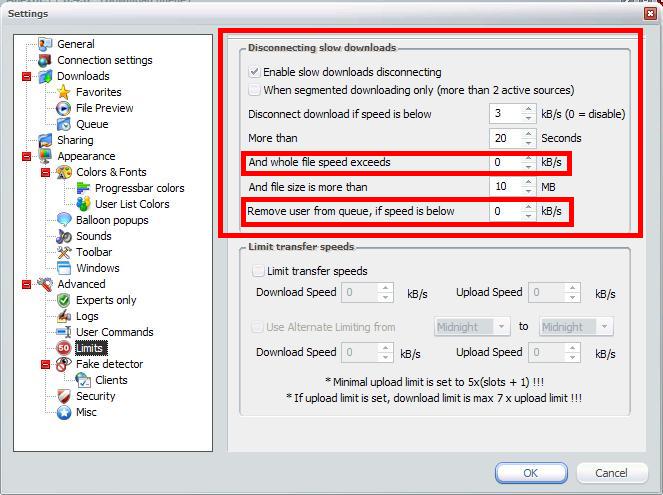
I want the "Disconnecting slow downloads" to behave as follows:
Disconnect if speed from user is below 3kb/sec reguardless of total file speed
And never remove anyone from queue.
I've included a screenshot, have I done it correctly?.
Thanks a lot. :P
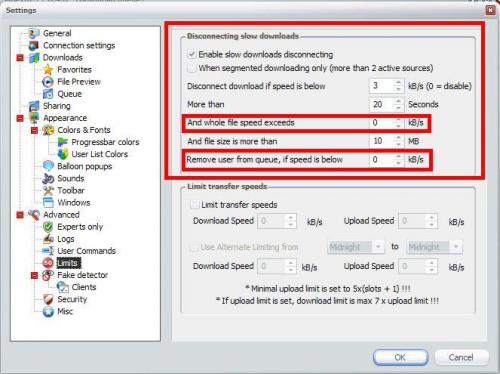
-
a) it's already there yes, I will fix the crash. But you will still get messages about corruption until you fix the problem in your PC.I have tried "Manual settings of number of segments set to "1" and had the same problems.
But I don't think I've tried "Enable multi source" set to "disabled".
I'll come back with the results later.
If this works then I'd like my "Detect and switch technique" idea to be added to Strong, if you really feel you cannot fix the corruption any other way.
-
The crash is the program fault, but the file corruption is some other HW/SW failureStrong could be modified or features added so it dosn't corrupt files - fact.
-
If it is a program fault, it MUST be sorted. But if my theory is right (and you are just downloading crap, except when you use SDC/Apex), I am very happy. You can download what you want, unfortunately there are many as you, some of them will reshare the crap, and we all will end in crap.IF I am right with this explanation, it is like not supporting NMDC filelists - just for good.
These files people are sharing are clearly not corrupt or garbage data since I have watched them all the way through without any problems whatsoever (DivX,Xvid Avi files) and have checked the TTH against the bittorrent release where possible.
Maybe your trying to touch another topic here - "Crap" is a matter of taste. I dont want censorship in my P2P client software thanks.
-
DC++ and SDC+/ApexDC++ are completely different applications:a) DC++ checks TTH tree only and does something during resume, so there's only minimum chance to figure out that the file is corrupted
StrongDC++ has different download techniques than DC++. It means that StrongDC++ accesses different HDD/memory areas, so it can walk into some corrupted part in different time than DC++.Thanks we got to the bottom of it: There are solutions
- "Fix" StrongDC++'s download techniques.
- Include the standard DC++ download techniques as an option. (I'd like this to be done anyway as a backup)
Ideal solution as said above I think - if you cannot fix strongs techniques:
Detect corrupted file when it says "corruption detected at position" then erase the file and temp file then Re add it and start again using standard DC++ download techniques
Detecting the corrupt file would be easy - just see which one is downloading the same chunk over and over.
-
If your theory is correct then there needs to be a way of disabling it since Its having false positives on corruption detection or better yet, fix it.
Either way
I tested (downloaded) a set of known "problem" files in Strong and Apex - all fail
I tested (downloaded) the exact same set of files in regular DC++ in the same hubs from the same users - all succeed and are perfect copies of the files. - I have even checked the TTHs against files that are available on bittorent and have downloaded with bittorent.
So you think my perfect copy is "crappy" eh? what a joke.
And this testing continues
My Conclusions so far: any file that fails to download in strongdc also fails in apex but suceeds in regular dc++ (and is a perfect copy).
Thank goodness for the regular dc++ client - I'll download whatever files I want thankyouverymuch.
-
Downloads > Queue > Segment Downloading > "Enable multi-source" set to "Disabled"
There you go :)
-
The crash must be caused by that corruption. But that corruption must be caused by some failure in your PC.DC++ regular client is working (sucessfully completes all downloads) with these problem files and ALL other files without corruption messages so I have to disagree, I have zero problems with other segmenting download: http, bittorrent or anything else at all on this PC.:
So can you elaborate in full detail please on why you are so certain it "must be caused by some failure in your PC"?
 Obviously your claim cannot be proven or disproven until there is Lots of results from lots of testing, you havn't yourself yet, correct?
Obviously your claim cannot be proven or disproven until there is Lots of results from lots of testing, you havn't yourself yet, correct?To those affected: My workaround for this is to run plain DC++ alongside strong/apex, delete the problem files from strong/apex queue and add them to your dc++ - temporarily disconnecting from hubs in strong/apex and connecting to hubs in dc++ until the strong/apex problem files complete sucessfully and then disconnect from hubs in dc++, connect to hubs in strong/apex
-
Does it do a mess for all users or only if the segment is downloaded from one certain user?Have you tried downloading other big file if it downloads ok?
1. Once "corruption is detected at positon" the download always fails from all sources, even with files with over 150 sources (users).
2. I download about 50 files a day all of those are in the 100mb-300mb range, 3-5% fail as said above.
-
Great. Single segment downloads are giving the same corruption messages - no problem in regular DC++.
-
I'm still not having any problems with the regular dc++ client, is there a way to force selected files to have only one segment, will you add this feature if its not there and that is if this bug is not completly fixed.
although maybe its not a bug in segmenting but a bug elsewhere in the download process, but we wont know until we test with single segment downloading.
Otherwise I'm forever stuck using regular dc++ client because of those 3-5% of files that fail in apex, strong & revconnect.
Also the client should tell you exactly what file the corruption is detected rather than the "corruption detected at position" and having to observe the transfers and find the one thats downloading the same chunk repeatedly
then at least I could continue using the client by queuing those quickly identified corrupted files in regular dc++, it would take way too much time otherwise.
Update: Settings>Downloads>Queue>Manual number of segments "1" works to set new downloads to single segment I'll report back results later.
Idea: If the client can detect which file is corrupting then it could for example pause the file to prevent crashing or automatically erase and re add the file in single segment mode.
-
@Big Muscle: As far as I know It happens only when downloading those few problematic files, It occurs at random intervals whilst these problematic files are running, downloading the same chunk of the file over and over again, crashing after downloading the same chunk maybe 10 times or 100 times.
I have tried these same files in all segmenting clients I know of - always fails.
Tried these files in plain vanilla DC++ with no segmenting and it worked first time, no corruption messages, no crashes. Small possibility remains that there is a few problematic users on the hub and downloading from them with segmenting or regular client hoses the download and causes crash and that they were all offline when I tested with regular client and thats why they all worked, doubt it though.
Update: Incase you havn't encountered some problem files for testing here are some examples:
search " mushishi 03 .a" and get file with TTH: HBBAHIWV56PEJQD5H6S6J4WAFQ2J3ELRNYBMJUA magnet:?xt=urn:tree:tiger:HBBAHIWV56PEJQD5H6S6J4WAFQ2J3ELRNYBMJUA&xl=189263872&dn=%5BC1%5DMushishi_-_03%5BXviD%5D%5BF334DBDF%5D.avi
search " ghost in the shell 24 .a" and get file with TTH: FY6T6IN2MEZCXWCNDL6HMAWP4HX6I2RRXRNBY2Y
magnet:?xt=urn:tree:tiger:FY6T6IN2MEZCXWCNDL6HMAWP4HX6I2RRXRNBY2Y&xl=186181632&dn=Ghost+in+the+Shell+-+Stand+Alone+Complex+-+24+%5BLMF%5D.avi
hubs with these files:
testhub.otaku-anime.net:555
public.otaku-anime.net:555
walhalla.otaku-anime.net:555
shinto.total-anime.net:666 (requires registration to search)
-
I have this exact same problem - is there anyway to download these problem files? someone has made a patch or workaround? or?
I have attached my crash report and included a bit of it here;
Always the same error recurring on same few TTHs.
Code: c0000005 (Access violation)
Version: 0.4.0 (2006-12-24)
Major: 5
Minor: 1
Build: 2600
SP: 2
Type: 1
Time: 2007-03-19 04:42:30
TTH: YBP45KNMY2PE64J2ZH7A77UJFMDBI4A4FN657VI
d:\cvs\apexdc++\apexdc\client\filechunksinfo.cpp(100): FileChunksInfo::addChunkPos
d:\cvs\apexdc++\apexdc\client\chunkoutputstream.h(64): ChunkOutputStream<1>::write
d:\cvs\apexdc++\apexdc\client\filteredfile.h(137): FilteredOutputStream<UnZFilter=0x02961018,1>::write
d:\cvs\apexdc++\apexdc\client\downloadmanager.cpp(692): DownloadManager::on
d:\cvs\apexdc++\apexdc\client\userconnection.h(411): UserConnection::on
d:\cvs\apexdc++\apexdc\client\speaker.h(68): Speaker<BufferedSocketListener>::fire<BufferedSocketListener::X<3>=0x03FAFE00,unsigned char *=0x03FAFEA8,int>
d:\cvs\apexdc++\apexdc\client\bufferedsocket.cpp(260): BufferedSocket::threadRead
d:\cvs\apexdc++\apexdc\client\bufferedsocket.cpp(528): BufferedSocket::run
d:\cvs\apexdc++\apexdc\client\thread.h(133): Thread::starter
f:\rtm\vctools\crt_bld\self_x86\crt\src\threadex.c(348): _callthreadstartex
f:\rtm\vctools\crt_bld\self_x86\crt\src\threadex.c(326): _threadstartex
[Crash] Apex 0.4.0
in Pre 1.0 Reports
Posted
Im replying in the feature requests forum.
Blegh I should have kept it here and started a new thread, oh well.
I have asked for those threads to be moved here.